

El mundo se ha vuelvo mas global y complejo, donde todo esta controlado por software desde aviones a autos, cada dia dependemos más y más de un software que es poco confiable y costoso de mantener, si no hacemos nada, seguiremos teniendo graves accidentes como el de los Boeing 737Max.
Nuestras vidas están siendo afectadas por la calidad del software. Conociendo que el 40% de los errores de software son errores de diseño, necesitamos una arquitectura de software que oriente el desarrollo de software de calidad, junto al problema de escalabilidad y disponibilidad que existe en la industria del software.
Desde el nacimiento de la computadora en 1938, al dia de hoy, 2019, ha habido un enorme avance en la capacidad de procesamiento (cantidad de operaciones por segundo) que puede realizar una computadora, pasamos de menos de 1 a 187.000.000.000.000.000 (187 mil millones de millones). Incluso una computadora casera procesa 135.000 millones. No ha sido lo mismo en la industria del desarrollo del software, muchos programas son codificados hoy en día de la misma forma que se hacia hace 30 años. El desarrollo del hardware va mas rápido que el software, y esto ralentiza el avance de la humanidad.
El problema de la escalabilidad no es solamente cuando conectamos varias computadoras, los fabricantes de procesadores ante la dificultad de fabricar procesadores mas rápidos, para aumentar la potencia están agregando mas procesadores en paralelo, estos se llaman núcleos, incluso los teléfonos tiene procesadores de varios núcleos, y ya en el 2019 se desarrollo un CPU con 400.000 núcleos.
Si tuviéramos una maquina del tiempo y trajéramos un desarrollador de software y un desarrollador de hardware de hace 30 años, el desarrollador de software se actualizaría en un par de horas y podría empezar a trabajar, en cambio un desarrollador de hardware tendría que pasar meses estudiando las nuevas técnicas para poder actualizarse. ¿porque sucede eso? una de las razones es que un hardware mal diseñado significaría una gran perdida para la empresa fabricante y por eso, en el diseño de hardware participan las mentes mas brillantes, en cambio un software mal diseñado puede cambiarse de un momento a otro, incluso hacer un software medianamente bueno y con fallas es un gran negocio, ya que permite vender el mismo software varias veces con la excusa de que la nueva versión soluciona las fallas de la versión anterior.
Evolución de la arquitectura de software
Al principio el software funcionaba en una computadora donde todo estaba bajo control del desarrollador. Ante el problema de permitir que el software funcionara en diversos tipos de computadoras, se desarrollaron los sistema operativos, esto también permitió que varios software se ejecutaran en el mismo computador. Cada etapa agrega un nuevo nivel de facilidades de programación así como mayor complejidad y fuente de fallas.
Después llego la arquitectura cliente – servidor, donde una parte de los cómputos los realiza el computador servidor y otra parte en el computador cliente, esto agrega otro grado de complejidad, ya que aunque ambos están bajo control del programador la conexión entre estos dos computadores por una red de datos implica una nueva fuente de fallas (incertidumbre).
Analizando esta resumida y parcial evolución de la arquitectura de desarrollo de software podemos pronosticar que la nueva arquitectura de software, va a traer nuevas facilidades y otra capa de complejidad.
En resumen los problemas que tenemos son:
- Software monolítico gigantesco, lento, que cada vez cuesta mas dinero mantener o mejorar.
- Baja probabilidad de concurrencia y disponibilidad.
- Usuarios con privilegios lo cual no permiten una auditoria confiable.
- La red es inconfiable e insegura, no es homogénea y su topología cambia, su demora «Latency» no es cero, su ancho de bando es finito y el costo de transporte no es cero.
Arquitectura Orgánica
Tal vez existan muchas soluciones y una sola arquitectura no sirva para todo, para nosotros, la solución al problema de calidad, escalabilidad y complejidad es La Arquitectura Orgánica.
Hemos combinado diferentes avances en arquitectura, patrones de diseño y metodologías de software que en nuestra opinión son complementarios, y llamamos a esta arquitectura «orgánica» ya que vemos cierta similaridad con la forma en que funcionan las células biológicas, incluso en la forma en que se toman decisiones colectivas.
El punto clave de nuestra arquitectura no es que funcione o que sea eficiente, es que sea «mantenible» por los desarrolladores, es decir maximizar la funcionalidad y la flexibilidad a la vez que se minimiza el esfuerzo. Esto se logra con abstracciones claras, bien definidas y separadas, ya que nosotros no partimos con la suposición que todo esta bajo control del desarrollador, sino todo lo contrario, van a existir cambios en los requerimientos de software, fallas e incertidumbres y es el deber del desarrollador de software prepararse para estos escenarios, y todo esto debe de ser lo mas transparente posible al usuario final, lo menos dramáticos posibles, tratando que sean imperceptibles por el usuario final.
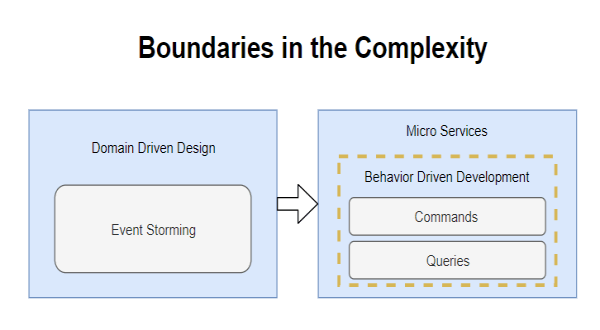
Atacar el problema de la complejidad comienza la metodología «Domain Driven Design» de EricEvans, que nos permite establecer el dominio y los limites «Boundaries» de todos los «Micro Servicios» del sistema. También nos ayudamos con la metodología complementaria «Event Storming» y obtenemos al final los «Micro Servicios» que vamos a implementar.
El siguiente paso es implementar estos «Micro Servicios» y para ello usamos la metodología «Behavior Driven Development» donde lo primero a desarrollar son las pruebas que nos van a permitir comprobar el buen funcionamiento de nuestro «Micro Servicio», Aquí también comienza la separación de los comandos «Commands» de las consultas «Queries» en nuestro «Micro Servicio», también lo podemos ver como la separación del lado de escritura del lado de lectura, así como la separación de la funcionalidad de los datos.
La funcionalidad se separa de la data, debido a que ambos son contradictorios y complementarios, para entenderlo mejor recomendamos leer a Robert C. Martin (Uncle Bob) en su articulo sobre «Classes vs. Data Structures» recordemos que buscamos la «mantenibilidad» del código y estas separaciones son la clave para lograrlo, es también la misma razón por la que la programación funcional se ha puesto de moda.
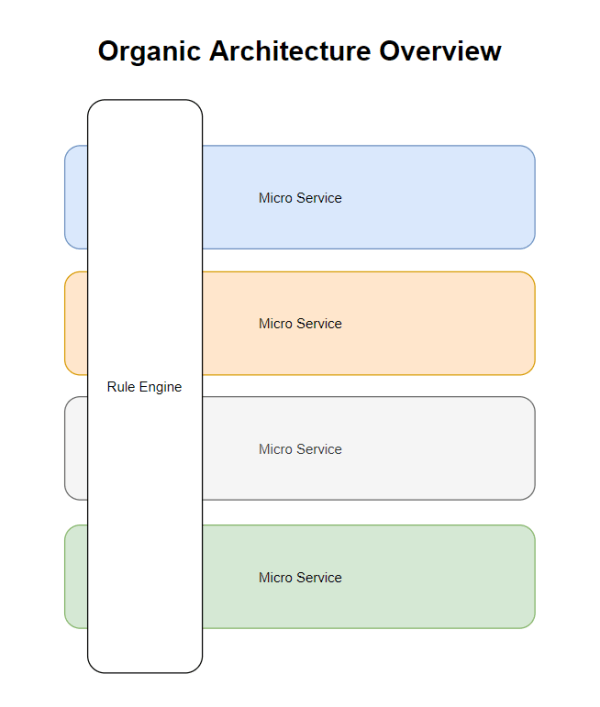
Al obtener nuestros «Micro Servicios» le agregamos otro Servicio Adicional el «Rule Engine» que es un servicio transversal a todos nuestros Micro Servicios, el «Rule Engine» nos permite componer funcionalidad transversal a todos nuestros Micro Servicios, así obtenemos la capacidad de adaptarnos a requerimientos adicionales de los usuarios de nuestro sistema complejo sin tener que volver a re analizar y desarrollar todo el sistema. El «Rule Engine» es una idea antigua, nuestra innovación consiste en esta relación que le damos con los «Micro Servicios» y aunque parece que esta en contra de la metodología DDD que busca el desacoplamiento entre «Micro Servicios» lo que hace es complementarlos sin acoplarlos.
Con el «Rule Engine» agregar nueva funcionalidad transversal (que afecte a varios Micro Servicios) se vuelve mas sencillo, es agregar funcionalidad al «Rule Engine» y agregar la interfaz y funcionalidad requerida en los Micro Servicios Implicados.
El «Rule Engine» no es un supervisor de los Micro Servicios, es mas bien como un Meta Servicio que compone información propia y de otros servicios.
Micro Servicio
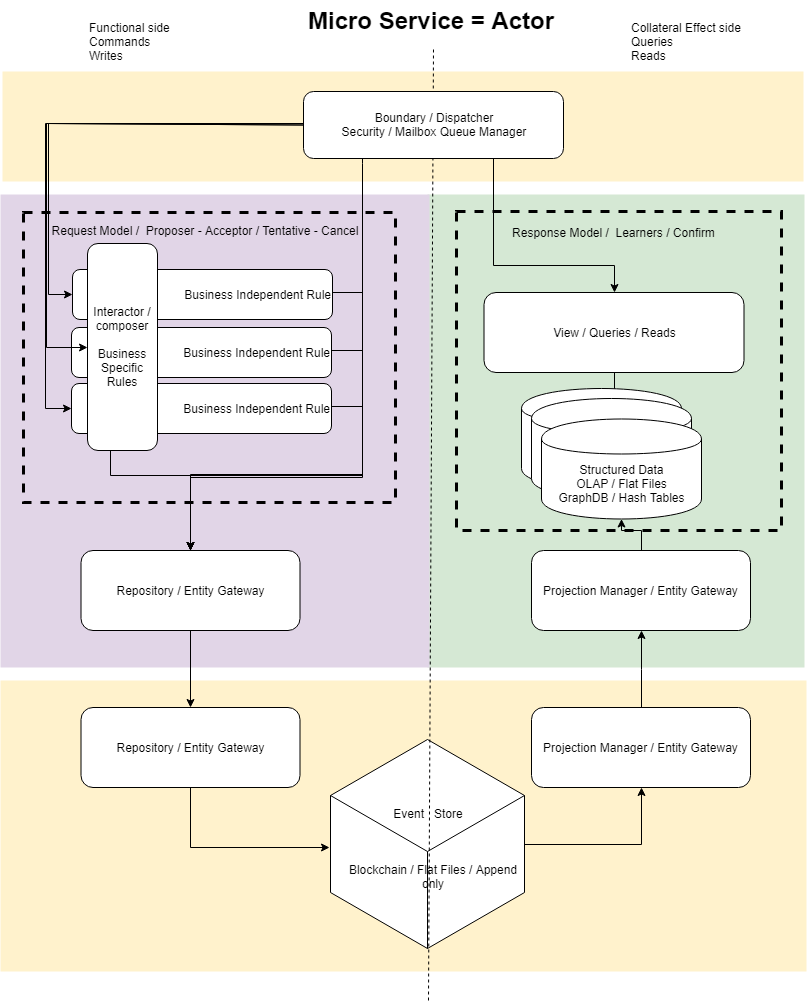
Ahora si llegamos al corazón de nuestra arquitectura para solucionar el problema de la escalabilidad.
Combinamos el patron CQRS + Event Sourcing + Actor Model Programming + BlockChain.
Helland en su articulo «Life Beyond Distributed Transactions» con su gran experiencia nos introduce a la solución al problema de la escalabilidad y nuestra arquitectura continua este trabajo.
CQRS «Command Query Responsibility Segregation» + «Event Store» es el trabajo de Greg Young donde a la separacion de la lectura de la escritura se le agrega «Event Sourcing» para tener la flexibilidad de diversas proyecciones de la misma data, esta data ahora se almacena de forma cruda en un «log», «Event Store» al que solo se le puede agregar data (esta data son hechos), sin actualizaciones de ningún tipo.
Una de las facilidades que nos brinda el «Event Store» es mejora aún mas esta separación de funcionalidad y data, ya que permite tener múltiples representaciones optimas de la misma data (Proyecciones) que esta en el Event Store.
El «Event Store», es ahora la fuente de la verdad, pero no es accesible de forma externa, lo que nos lleva al problema de la consistencia eventual, es decir los datos que obtienen de las de consultas que se hacen en el lado de la lectura eventualmente estarán actualizados, ya que son una proyección de la data, pero no la fuente de la verdad.
En el lado de los comandos, se separa la logica del negocio en reglas independientes del negocio, de las reglas especificas del negocio, que son transversalmente ejecutadas por un Interactor / Composer que las aplica de forma especifica. Esta abstraccion tiene la misma finalidad que el «Rule Engine» en relación a los «Micro Servicios» del diagrama anterior.
Vaughn Vernon, es otro experto que nos ha servido de inspiración, ya que también llega a la conclusión de la necesidad de aplicar «Actor Model» un diseño de 1973, y en palabras de Alan Kay «Actor model retiene mas de lo que yo pensé son las ideas importantes en programación de objetos» Así, Actor Model es programación de objetos hecho de la forma correcta.
«Actor Model», se agrega para darnos su funcionalidad de concurrencia y supervision. El «Mailbox» de «Actor Model» es nuestro «Boundary / Dispatcher / Security / Mailbox» que recibe los mensajes y los guarda en el «Event Store», y el «Event Store» nos permite hacer el ciclo de vida del «Actor», es decir creación y destrucción de «Actores» de forma transparente, ya que el nuevo «Actor» puede continuar la ejecución hasta donde se quedo según lo presenta la proyeccion del Event Store.
Hasta ahora el problema de «Actor Model» ha sido la creacion y destrucción dinamica de «Actores» y en segundo lugar las pruebas y el debug, esto queda solucionado con un «Event Store» que al implementado como un BlockChain distribuido entre una cantidad variable de actores dinámicos, quedando solo el problema de la consistencia eventual. Esta idea de conectar «Actor Model» con un log distribuido (blockchain) es otra innovación nuestra.
Queda por desarrollar en esta arquitectura el «Workflow» de mensajes, tanto de los propios de «Actor Model», como los mensajes entre «Micro Servicios», este Workflow esta contemplado en la arquitectura, pero no esta detallado, existen trabajos sobre «Workflow» transaccionales (Tentative – Cancel – Confirm). Para nosotros esto es ingeniería de detalle, que vamos a desarrollar cuando hagamos realidad esta arquitectura que hemos diseñado.
Nota: El problema de syncronizar una bitacora distribuida, tanto la industria como el mundo académico lo consideran resuelto con los algoritmos Paxos y RAFT y para los consensos bizantinos (con fallas debido a participantes maliciosos) PBFT, HoneybadgerBFT, BEAT ó HotStuff .

Beneficios de la Arquitectura Orgánica
- Máxima funcionalidad y flexibilidad a la vez que se minimiza el esfuerzo, lo que conlleva a reducción de costos.
- Transparencia en las actualizaciones y fallas – reinicio de servicio, lo que aumenta la disponibilidad.
- Reducción del acoplamiento entre micro servicios.
- Permite el Monitoreo del software.
- Centrado en el modelo mental de Eventos y Actividades.
- Reconstrucción y viaje en el tiempo, lo que permite Auditoria y Debuging.
- Buena separación entre lógica de negocio, estructuras de data y componentes.
- Optimización de las estructuras de data (proyecciones).
- Rompe el embotellamiento entre lecturas y escrituras.
- Eleva la posibilidad de concurrencia.
- Independencia entre los diversos equipos de desarrollo (cada uno con su «Micro Servicio»).
- Simplifica y endurece los mensajes.
Esta arquitectura requiere el apoyo de un Framework / Librería, que tome el peso del código que conoce los detalles del manejo de la escala, dejando al desarrollador la lógica del negocio con sus proyecciones. El flujo de trabajo de los mensajes para el manejo de la consistencia eventual y demás mensajes asíncronos entre «Micro Servicios», puede implementarse usando la libreria nng y la encriptación de la comunicación con la libreria wireguard .





